









前言
使用本教程请严格遵守中华人民共和国和美利坚合众国法律
Troubleshooting any problem without the error log is like driving with your eyes closed.
在没有错误日志的情况下解决任何问题无异于闭眼开车。
--Apache HTTP Server Documentation Getting Started
2024/01/06更新 适配2.3版本
本文的编写的过程中假定了一些前提:
1. 您拥有较高的连通性的网络,可以正常访问PIP源 GitHub等站点
2. 读者拥有一定计算机操作基础,了解GitHub、简单的编程开发操作,本文省略的细节都应当是能在网络上非常容易查找到答案的
关于本文的一些关于AI训练的专业词汇,我在「词汇表」部分都尽量的按照我的理解进行了一些解释
本文在编写的时候是依照2.1版本编写的,写到一半的时候2.2版本发布了,所以最终是按照2.2版本。但是应当也可以在2.1版本工作 如果在1.x版本,基本上本教程也同样使用,仅仅是一些储存路径的区别
DEMO
基于Bert-VITS2 1.1
AI 以里illi
基于Bert-VITS2 2.2
AI Hanser
要求
- Windows或者Linux电脑(本教程基于Windows编写)
- NVIDIA GPU 或 租赁NVIDIA GPU服务器 或 Google Colab等平台
- 较高的连通性的网络(访问GitHub Huggingface等平台)
- 至少30G的磁盘空间 建议100GB以上的SSD空间
数据准备
首先先准备满足以下要求的音频文件
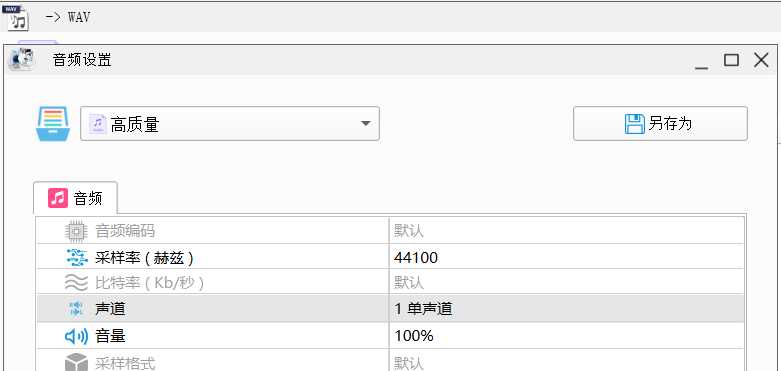
- WAV格式
- 采样率44100Hz
- 单声道
请确保您对训练数据拥有合法权利
可以使用FFmpeg或者格式工厂对音频进行转码
准备好满足条件的音频之后就需要对音频进行切片 每个音频大概5-10s
可以使用
https://github.com/flutydeer/audio-slicer
不过也可能切出来的音频过大
我一般会删掉大于10M的切片 其他的大一点超过10s问题也不是很大
数据标注
接下来就是要对刚刚准备的切片好的数据集进行标注了
简单来说就是要把音频和文字对应上就相当于 「赛博活字印刷术」
这边可以直接使用领航员未鸟制作的AI标注包 直接用AI来识别音频的语音来标注
https://www.bilibili.com/video/BV1uz4y1j7q7/
https://www.bilibili.com/video/BV1sG41127pV/
完成后你应该得到clean_barbara.list文件 这个就是音频对应的标注数据了
准备环境
NVIDIA CUDA 和 cuDNN
为了减少报错等奇奇怪怪的问题 强烈建议使用CUDA11.7版本
下载链接:
https://developer.nvidia.com/cuda-11-7-0-download-archive
按照指引下载安装即可
前往下面的链接注册NVIDIA账号然后下载适用于CUDA 11.x的cuDNN library
https://developer.nvidia.com/cudnn
一般下载 Local Installer for Windows (Zip)即可
cuDNN的安装步骤可以阅读https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html 官方安装教程 同时网络上也有很多类似的文章
安装完成后应当能通过cmd命令nvcc --version 显示CUDA的信息
Python3.8
https://www.python.org/downloads/release/python-3810/
一般来说下载Windows installer (64-bit)
跟随安装向导安装即可
注意勾选「PIP」和「Add Python to environment variables」这两个复选框
GIT
https://git-scm.com/downloads
跟随安装向导安装即可
PyCharm(Optional)
我将使用PyCharm作为代码编辑器 这不是必须的 但是后续都将在PyCharm中操作
同样的使用VSCode或者其他文本编辑器都可以作为替代品
但是PyCharm应当能在部署过程中简化一些繁琐的步骤(VSCode也应当可以)
安装项目源代码
https://github.com/fishaudio/Bert-VITS2
接下来在git bash使用 git clone https://github.com/fishaudio/Bert-VITS2
或者直接下载最新版本的release包解压到文件夹
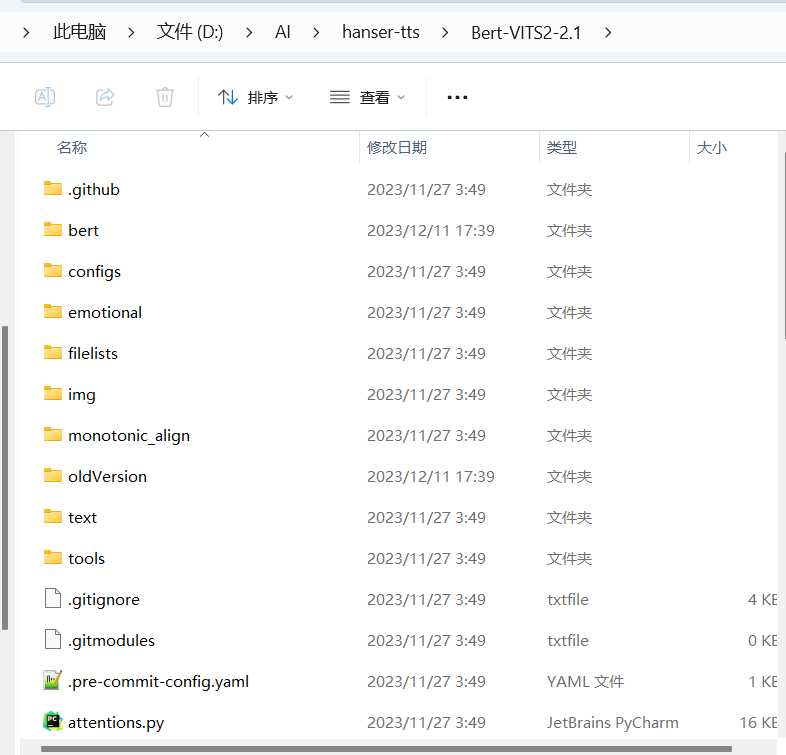
然后使用打开PyCharm 新建项目 如图选择刚刚的文件夹 选择Python虚环境 Python3.8
PyCharm应当自动创建虚环境完成部署
点击页面底部的「终端」 命令行开头应当是(venv)
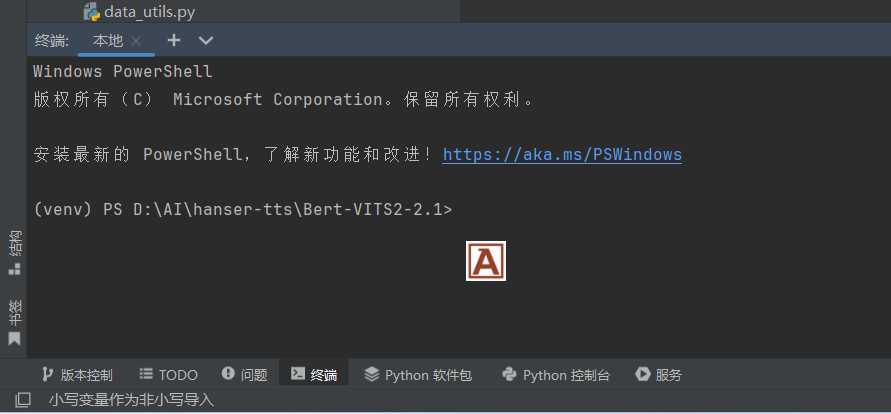
补充项目缺失的文件
- 依照 https://huggingface.co/cl-tohoku/bert-base-japanese-v3/tree/main 补充 \Bert-VITS2\bert\bert-base-japanese-v3 路径下所有缺失的文件
- 依照https://huggingface.co/cl-tohoku/bert-large-japanese-v2/tree/main 补充 \Bert-VITS2\bert\bert-large-japanese-v2 路径下所有缺失文件
- 依照https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/tree/main 补充 \Bert-VITS2\bert\chinese-roberta-wwm-ext-large 路径下所有缺失文件
- 依照https://huggingface.co/ku-nlp/deberta-v2-large-japanese/tree/main 补充 \Bert-VITS2\bert\deberta-v2-large-japanese 路径下所有缺失文件
- 依照https://huggingface.co/ku-nlp/deberta-v2-large-japanese-char-wwm/tree/main 补充 \Bert-VITS2\bert\deberta-v2-large-japanese-char-wwm 路径下所有缺失文件
- 依照https://huggingface.co/microsoft/deberta-v3-large/tree/main 补充 \Bert-VITS2\bert\deberta-v3-large 路径下所有缺失文件
-
(仅2.3版本)依照https://huggingface.co/microsoft/wavlm-base-plus/tree/main 补充 \Bert-VITS2\slm\wavlm-base-plus 路径下所有缺失文件
-
(仅2.1版本)依照https://huggingface.co/audeering/wav2vec2-large-robust-12-ft-emotion-msp-dim/tree/main 补充 \Bert-VITS2\emotional\wav2vec2-large-robust-12-ft-emotion-msp-dim 路径下所有缺失文件
- (仅2.2版本)依照https://huggingface.co/laion/clap-htsat-fused 补充 \Bert-VITS2\emotional\clap-htsat-fused 路径下所有缺失文件
安装 PyTorch
打开PyCharm终端执行
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
安装依赖
打开PyCharm终端执行
pip3 install -r requirements.txt
或者可以直接点击PyCharm提示的「安装要求」

准备训练
导入文件
按照以下路径创建文件夹
\Bert-VITS2\Data\audios\raw
把所有切片音频放入此文件
把标注的.list文件放入 \Bert-VITS2\Data\filelists 文件夹
编辑根目录下的config.yml(默认default_config.yml)
transcription_path: "filelists/标注文件名.list"
修改为你的标注文件的文件名
重采样 resample
通过绿色箭头 运行resample.py
2.3版本为resample_legacy.py

文本预处理 preprocess_text
这里好像有bug 或者说也可能是我手动配置了一些他应该自动配置的步骤?
这一步需要把\Bert-VITS2\Data\audios\wavs内的所有文件复制到\Bert-VITS2\dataset\说话人名称(手动创建缺失的文件夹)
通过绿色箭头 运行preprocess_text.py
生成BERT bert_gen
通过绿色箭头 运行bert_gen.py

生成情感 clap_gen (2.3版本跳过此步骤)
通过绿色箭头 运行clap_gen.py
「1.x版本无此步骤」「2.0-2.1版本应当运行emo_gen,但我未测试过相关版本」

训练
下载底模
前往项目发布页https://github.com/fishaudio/Bert-VITS2/releases
按照说明下载底模,放置到\Bert-VITS2\Data\models文件夹内(手动创建)
修改配置
打开 \Bert-VITS2-2.2-fix\Data\config.json
我们一般主要关注以下的设置
"log_interval": 50, #这个是训练是每运行多少step之后在命令行输出一次最新状态
"eval_interval": 500, #这个可以简单理解成每运行多少step之后保存一次模型文件
"batch_size": 16, #这个是一批处理的数量 如果遇到训练时提示显存溢出请调小,个人测试一般是 显存(单位GB) >= batch_size设置值 >= 显存(单位GB)/2 然后一般是2的指数倍
开始训练
如果在本机训练 直接运行train_ms.py
这里介绍一下如何使用Google Colab训练
Colab其实也是一样,把整个项目打包
主要是venv文件夹不需要打包 这个是在Windows下的Python环境
然后就是把压缩包上传Google Drive,导入,解压
然后就是安装环境
PyTorch
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
依赖
pip3 install -r requirements.txt
之后也是直接运行train_ms.py
推理
训练后模型文件默认是存在\Bert-VITS2\Data\models
里面G_XXXX.pth xxxx数字最大的就是目前训练进度最新的模型文件了
记录这个文件名
编辑根目录下的config.yml(默认default_config.yml)
webui:
model: "models/G_8000.pth"
修改为你的模型文件的文件名
最后运行webui.py即可进行推理
一些关于我训练的看法
关于数据集质量
一般来说,我在训练DEMO的两个模型的是时候都是使用对应UP的直播录像,然后对相关数据进行了挑选
大概时间长度来说,对应直播路线的质量我个人觉得有4-8小时左右的音频就差不多了 效果不会太差
AI 以里illi的数据集还算比较好,以里直播说话的语气语调都有比较一致,并且没有太多的BGM干扰,事实上并没有经历太多的对数据集的挑选整理
AI Hanser的数据集是怎么说呢 挺折腾的 由于hanser在直播过程中语气变化比较明显 包括早期直播和近期直播的声线有着不同 另外直播中还有较大声BGM干扰 BGM声音相对较少的读书回的语气又不太是我最喜爱的hanser的声线,有点过于「正经」 我其实最后是挑选了几次手机直播的录播 但是手机直播的收音效果远不如麦克风 因此实际音频质量也并不是很好 因此实际上AI hanser的模型训练是经过了非常多次的失败然后重新训练的
总之 语气的明显变化 非预期的发音声线 BGM 较差的收音 都会严重的影响最终训练的质量
关于训练进度
一般可能每2000到5000step就做下推理 看看效果 如果效果太差及时止损 回炉重造
训练step数量是受到你的batch_size设置影响的,batch_size越大,理论上只需要更少的step就可以得到比「batch_size更小的训练者」达到相同的效果
所以一般衡量是看epoch,一般100 -200就可以有个比较好的效果
如果训练次数过多可能会出现「过拟合」的问题导致效果变得更差
词汇表
step:步数 就是训练了多少次,训练部署会呈现在保存的模型文件的「G_xxxx.pth」数字上 还有训练过程中的进度上 每step就是处理完成「一批」
batch_size: 每「一批」的大小,这个数字越大,每一步处理的数据越多
epoch: 代 这个数字每增加1,表示计算机对次模型的所有数据完成了一次计算。batch_size越大,就相当于一次处理的数据多,这样全部数据可以被划分为更少的「批」的数量,因此只需要更少的step就可以完成每epoch
过拟合:「过于紧密或精确地匹配特定数据集」就是相当于说你训练的模型过度的对齐了特定的数据,而失去了AI对「不确定性的可能性」的预测,或者可以理解成这个模型太专了,没有了泛用型
这用拙劣的模仿〇神的策划的操作举个例子,假设策划出了一个武器「不灭之钥」,然后这个武器的词条是「当红色头发的,会跳舞的,女性的,属于祖拜尔剧场的须弥角色使用的时候,伤害增加1000%,否则降低1000%」
鸣谢
Bert-VITS2项目:https://github.com/fishaudio/Bert-VITS2
领航员未鸟:https://space.bilibili.com/2403955
团子是咸鱼:https://space.bilibili.com/10685437


Comments | NOTHING